

Note
Go to the end to download the full example code.
Training a LeNet with Monte-Carlo Dropout¶
In this tutorial, we will train a LeNet classifier on the MNIST dataset using Monte-Carlo Dropout (MC Dropout), a computationally efficient Bayesian approximation method. To estimate the predictive mean and uncertainty (variance), we perform multiple forward passes through the network with dropout layers enabled in train mode.
For more information on Monte-Carlo Dropout, we refer the reader to the following resources:
Dropout as a Bayesian Approximation: Representing Model Uncertainty in Deep Learning ICML 2016
What Uncertainties Do We Need in Bayesian Deep Learning for Computer Vision? NeurIPS 2017
Training a LeNet with MC Dropout using TorchUncertainty models and PyTorch Lightning¶
In this part, we train a LeNet with dropout layers, based on the model and routines already implemented in TU.
1. Loading the utilities¶
First, we have to load the following utilities from TorchUncertainty:
the TUTrainer from TorchUncertainty utils
the datamodule handling dataloaders: MNISTDataModule from torch_uncertainty.datamodules
the model: lenet from torch_uncertainty.models
the MC Dropout wrapper: mc_dropout, from torch_uncertainty.models.wrappers
the classification training & evaluation routine in the torch_uncertainty.routines
an optimization recipe in the torch_uncertainty.optim_recipes module.
We also need import the neural network utils within torch.nn.
from pathlib import Path
from torch_uncertainty import TUTrainer
from torch import nn
from torch_uncertainty.datamodules import MNISTDataModule
from torch_uncertainty.models.lenet import lenet
from torch_uncertainty.models import mc_dropout
from torch_uncertainty.optim_recipes import optim_cifar10_resnet18
from torch_uncertainty.routines import ClassificationRoutine
2. Defining the Model and the Trainer¶
In the following, we first create the trainer and instantiate the datamodule that handles the MNIST dataset, dataloaders and transforms. We create the model using the blueprint from torch_uncertainty.models and we wrap it into an mc_dropout. To use the mc_dropout wrapper, make sure that you use dropout modules and not functionals. Moreover, they have to be instantiated in the __init__ method.
trainer = TUTrainer(accelerator="cpu", max_epochs=2, enable_progress_bar=False)
# datamodule
root = Path("data")
datamodule = MNISTDataModule(root=root, batch_size=128)
model = lenet(
in_channels=datamodule.num_channels,
num_classes=datamodule.num_classes,
dropout_rate=0.4,
)
mc_model = mc_dropout(model, num_estimators=16, last_layer=False)
3. The Loss and the Training Routine¶
This is a classification problem, and we use CrossEntropyLoss as the (negative-log-)likelihood. We define the training routine using the classification training routine from torch_uncertainty.routines. We provide the number of classes the optimization recipe and tell the routine that our model is an ensemble at evaluation time.
routine = ClassificationRoutine(
num_classes=datamodule.num_classes,
model=mc_model,
loss=nn.CrossEntropyLoss(),
optim_recipe=optim_cifar10_resnet18(mc_model),
is_ensemble=True,
)
4. Gathering Everything and Training the Model¶
We can now train the model using the trainer. We pass the routine and the datamodule to the fit and test methods of the trainer. It will automatically evaluate some uncertainty metrics that you will find in the table below.
trainer.fit(model=routine, datamodule=datamodule)
results = trainer.test(model=routine, datamodule=datamodule)
0%| | 0.00/9.91M [00:00<?, ?B/s]
1%| | 98.3k/9.91M [00:00<00:15, 641kB/s]
4%|▎ | 360k/9.91M [00:00<00:06, 1.51MB/s]
7%|▋ | 721k/9.91M [00:00<00:04, 2.15MB/s]
15%|█▌ | 1.51M/9.91M [00:00<00:02, 3.95MB/s]
25%|██▌ | 2.49M/9.91M [00:00<00:01, 5.45MB/s]
43%|████▎ | 4.26M/9.91M [00:00<00:00, 8.79MB/s]
59%|█████▊ | 5.80M/9.91M [00:00<00:00, 9.01MB/s]
92%|█████████▏| 9.11M/9.91M [00:01<00:00, 13.4MB/s]
100%|██████████| 9.91M/9.91M [00:01<00:00, 9.36MB/s]
0%| | 0.00/28.9k [00:00<?, ?B/s]
100%|██████████| 28.9k/28.9k [00:00<00:00, 374kB/s]
0%| | 0.00/1.65M [00:00<?, ?B/s]
6%|▌ | 98.3k/1.65M [00:00<00:02, 627kB/s]
20%|█▉ | 328k/1.65M [00:00<00:01, 1.12MB/s]
48%|████▊ | 786k/1.65M [00:00<00:00, 1.94MB/s]
100%|██████████| 1.65M/1.65M [00:00<00:00, 2.98MB/s]
0%| | 0.00/4.54k [00:00<?, ?B/s]
100%|██████████| 4.54k/4.54k [00:00<00:00, 9.70MB/s]
/home/chocolatine/actions-runner/_work/_tool/Python/3.10.16/x64/lib/python3.10/site-packages/lightning/pytorch/trainer/connectors/data_connector.py:425: The 'val_dataloader' does not have many workers which may be a bottleneck. Consider increasing the value of the `num_workers` argument` to `num_workers=19` in the `DataLoader` to improve performance.
/home/chocolatine/actions-runner/_work/_tool/Python/3.10.16/x64/lib/python3.10/site-packages/lightning/pytorch/trainer/connectors/data_connector.py:425: The 'train_dataloader' does not have many workers which may be a bottleneck. Consider increasing the value of the `num_workers` argument` to `num_workers=19` in the `DataLoader` to improve performance.
/home/chocolatine/actions-runner/_work/_tool/Python/3.10.16/x64/lib/python3.10/site-packages/lightning/pytorch/trainer/connectors/data_connector.py:425: The 'test_dataloader' does not have many workers which may be a bottleneck. Consider increasing the value of the `num_workers` argument` to `num_workers=19` in the `DataLoader` to improve performance.
┏━━━━━━━━━━━━━━┳━━━━━━━━━━━━━━━━━━━━━━━━━━━┓
┃ Test metric ┃ Classification ┃
┡━━━━━━━━━━━━━━╇━━━━━━━━━━━━━━━━━━━━━━━━━━━┩
│ Acc │ 86.350% │
│ Brier │ 0.38684 │
│ Entropy │ 1.64602 │
│ NLL │ 0.89530 │
└──────────────┴───────────────────────────┘
┏━━━━━━━━━━━━━━┳━━━━━━━━━━━━━━━━━━━━━━━━━━━┓
┃ Test metric ┃ Calibration ┃
┡━━━━━━━━━━━━━━╇━━━━━━━━━━━━━━━━━━━━━━━━━━━┩
│ ECE │ 0.38262 │
│ aECE │ 0.38262 │
└──────────────┴───────────────────────────┘
┏━━━━━━━━━━━━━━┳━━━━━━━━━━━━━━━━━━━━━━━━━━━┓
┃ Test metric ┃ Selective Classification ┃
┡━━━━━━━━━━━━━━╇━━━━━━━━━━━━━━━━━━━━━━━━━━━┩
│ AUGRC │ 2.467% │
│ AURC │ 3.027% │
│ Cov@5Risk │ 75.110% │
│ Risk@80Cov │ 6.162% │
└──────────────┴───────────────────────────┘
5. Testing the Model¶
Now that the model is trained, let’s test it on MNIST. Don’t forget to call .eval() to enable dropout at evaluation and get multiple (here 16) predictions.
import matplotlib.pyplot as plt
import numpy as np
import torch
import torchvision
def imshow(img):
npimg = img.numpy()
plt.imshow(np.transpose(npimg, (1, 2, 0)))
plt.axis("off")
plt.tight_layout()
plt.show()
dataiter = iter(datamodule.val_dataloader())
images, labels = next(dataiter)
# print images
imshow(torchvision.utils.make_grid(images[:6, ...], padding=0))
print("Ground truth labels: ", " ".join(f"{labels[j]}" for j in range(6)))
routine.eval()
logits = routine(images).reshape(16, 128, 10)
probs = torch.nn.functional.softmax(logits, dim=-1)
for j in range(6):
values, predicted = torch.max(probs[:, j], 1)
print(
f"MC-Dropout predictions for the image {j+1}: ",
" ".join([str(image_id.item()) for image_id in predicted]),
)
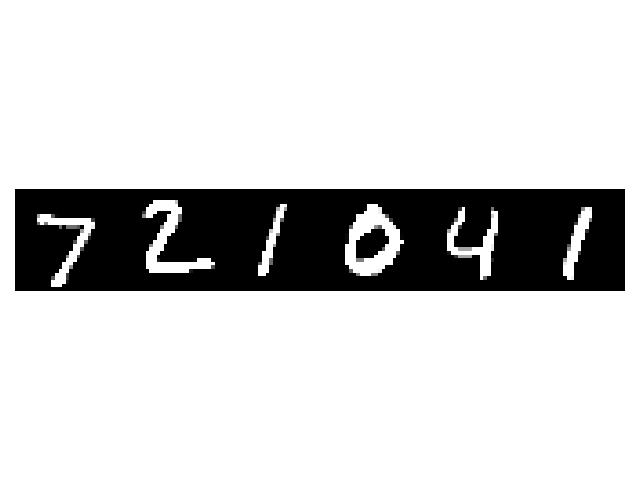
Ground truth labels: 7 2 1 0 4 1
MC-Dropout predictions for the image 1: 7 1 7 7 9 2 7 7 7 7 7 7 7 7 7 7
MC-Dropout predictions for the image 2: 2 2 2 2 7 2 2 2 2 2 2 2 6 2 2 2
MC-Dropout predictions for the image 3: 1 1 8 1 1 1 1 1 1 1 1 1 1 1 0 1
MC-Dropout predictions for the image 4: 7 0 0 0 0 0 0 0 0 0 8 0 0 0 0 0
MC-Dropout predictions for the image 5: 4 4 6 1 4 4 4 1 1 4 4 1 4 1 4 1
MC-Dropout predictions for the image 6: 4 1 8 4 1 1 1 1 1 1 1 1 1 1 1 1
Most of the time, we see that there is some disagreement between the samples of the dropout approximation of the posterior distribution.
Total running time of the script: (0 minutes 29.429 seconds)