

Note
Go to the end to download the full example code.
Improve Top-label Calibration with Temperature Scaling¶
In this tutorial, we use TorchUncertainty to improve the calibration of the top-label predictions and the reliability of the underlying neural network.
This tutorial provides extensive details on how to use the TemperatureScaler class, however, this is done automatically in the datamodule when setting the postprocess_set to val or test.
Through this tutorial, we also see how to use the datamodules outside any Lightning trainers, and how to use TorchUncertainty’s models.
1. Loading the Utilities¶
In this tutorial, we will need:
TorchUncertainty’s Calibration Error metric to compute to evaluate the top-label calibration with ECE and plot the reliability diagrams
the CIFAR-100 datamodule to handle the data
a ResNet 18 as starting model
the temperature scaler to improve the top-label calibration
a utility function to download HF models easily
If you use the classification routine, the plots will be automatically available in the tensorboard logs if you use the log_plots flag.
from torch_uncertainty.datamodules import CIFAR100DataModule
from torch_uncertainty.metrics import CalibrationError
from torch_uncertainty.models.resnet import resnet
from torch_uncertainty.post_processing import TemperatureScaler
from torch_uncertainty.utils import load_hf
2. Loading a model from TorchUncertainty’s HF¶
To avoid training a model on CIFAR-100 from scratch, we load a model from Hugging Face. This can be done in a one liner:
# Build the model
model = resnet(in_channels=3, num_classes=100, arch=18, style="cifar", conv_bias=False)
# Download the weights (the config is not used here)
weights, config = load_hf("resnet18_c100")
# Load the weights in the pre-built model
model.load_state_dict(weights)
<All keys matched successfully>
3. Setting up the Datamodule and Dataloaders¶
To get the dataloader from the datamodule, just call prepare_data, setup, and extract the first element of the test dataloader list. There are more than one element if eval_ood is True: the dataloader of in-distribution data and the dataloader of out-of-distribution data. Otherwise, it is a list of 1 element.
dm = CIFAR100DataModule(root="./data", eval_ood=False, batch_size=32, postprocess_set="test")
dm.prepare_data()
dm.setup("test")
# Get the full post-processing dataloader (unused in this tutorial)
dataloader = dm.postprocess_dataloader()
0%| | 0.00/169M [00:00<?, ?B/s]
0%| | 65.5k/169M [00:00<07:09, 394kB/s]
0%| | 229k/169M [00:00<03:47, 741kB/s]
0%| | 623k/169M [00:00<01:53, 1.48MB/s]
1%| | 1.38M/169M [00:00<00:55, 3.01MB/s]
1%|▏ | 2.16M/169M [00:00<00:41, 4.01MB/s]
3%|▎ | 4.39M/169M [00:00<00:19, 8.42MB/s]
4%|▍ | 6.36M/169M [00:01<00:15, 10.6MB/s]
6%|▋ | 10.8M/169M [00:01<00:08, 19.4MB/s]
9%|▉ | 15.2M/169M [00:01<00:05, 26.1MB/s]
11%|█ | 18.8M/169M [00:01<00:05, 25.4MB/s]
14%|█▍ | 23.4M/169M [00:01<00:04, 30.8MB/s]
16%|█▋ | 27.6M/169M [00:01<00:04, 33.7MB/s]
19%|█▊ | 31.6M/169M [00:01<00:04, 31.0MB/s]
21%|██▏ | 36.2M/169M [00:01<00:03, 35.0MB/s]
24%|██▍ | 40.4M/169M [00:01<00:03, 36.9MB/s]
26%|██▌ | 44.3M/169M [00:02<00:03, 32.8MB/s]
29%|██▉ | 49.0M/169M [00:02<00:03, 36.4MB/s]
31%|███▏ | 53.2M/169M [00:02<00:03, 38.0MB/s]
34%|███▍ | 57.2M/169M [00:02<00:03, 33.7MB/s]
37%|███▋ | 61.7M/169M [00:02<00:02, 36.6MB/s]
39%|███▉ | 66.4M/169M [00:02<00:02, 39.1MB/s]
42%|████▏ | 70.5M/169M [00:02<00:02, 34.4MB/s]
44%|████▍ | 75.0M/169M [00:02<00:02, 37.3MB/s]
47%|████▋ | 79.4M/169M [00:03<00:02, 34.0MB/s]
50%|████▉ | 84.0M/169M [00:03<00:02, 37.1MB/s]
52%|█████▏ | 88.1M/169M [00:03<00:02, 38.2MB/s]
55%|█████▍ | 92.1M/169M [00:03<00:02, 33.9MB/s]
57%|█████▋ | 96.8M/169M [00:03<00:01, 37.2MB/s]
60%|█████▉ | 101M/169M [00:03<00:01, 37.7MB/s]
62%|██████▏ | 105M/169M [00:03<00:01, 34.2MB/s]
65%|██████▍ | 110M/169M [00:03<00:01, 37.2MB/s]
67%|██████▋ | 114M/169M [00:03<00:01, 38.1MB/s]
70%|██████▉ | 118M/169M [00:04<00:01, 34.2MB/s]
72%|███████▏ | 122M/169M [00:04<00:01, 37.4MB/s]
75%|███████▍ | 126M/169M [00:04<00:01, 37.8MB/s]
77%|███████▋ | 130M/169M [00:04<00:01, 34.3MB/s]
80%|███████▉ | 135M/169M [00:04<00:00, 37.4MB/s]
82%|████████▏ | 139M/169M [00:04<00:00, 37.8MB/s]
85%|████████▍ | 143M/169M [00:04<00:00, 34.1MB/s]
87%|████████▋ | 148M/169M [00:04<00:00, 37.4MB/s]
90%|████████▉ | 152M/169M [00:04<00:00, 37.3MB/s]
92%|█████████▏| 156M/169M [00:05<00:00, 34.5MB/s]
95%|█████████▌| 161M/169M [00:05<00:00, 37.5MB/s]
97%|█████████▋| 165M/169M [00:05<00:00, 38.0MB/s]
100%|█████████▉| 169M/169M [00:05<00:00, 34.2MB/s]
100%|██████████| 169M/169M [00:05<00:00, 30.9MB/s]
4. Iterating on the Dataloader and Computing the ECE¶
We first split the original test set into a calibration set and a test set for proper evaluation.
When computing the ECE, you need to provide the likelihoods associated with the inputs. To do this, just call PyTorch’s softmax.
To avoid lengthy computations (without GPU), we restrict the calibration computation to a subset of the test set.
from torch.utils.data import DataLoader, random_split
# Split datasets
dataset = dm.test
cal_dataset, test_dataset, other = random_split(
dataset, [1000, 1000, len(dataset) - 2000]
)
test_dataloader = DataLoader(test_dataset, batch_size=32)
calibration_dataloader = DataLoader(cal_dataset, batch_size=32)
# Initialize the ECE
ece = CalibrationError(task="multiclass", num_classes=100)
# Iterate on the calibration dataloader
for sample, target in test_dataloader:
logits = model(sample)
probs = logits.softmax(-1)
ece.update(probs, target)
# Compute & print the calibration error
print(f"ECE before scaling - {ece.compute():.3%}.")
ECE before scaling - 9.478%.
We also compute and plot the top-label calibration figure. We see that the model is not well calibrated.
fig, ax = ece.plot()
fig.show()
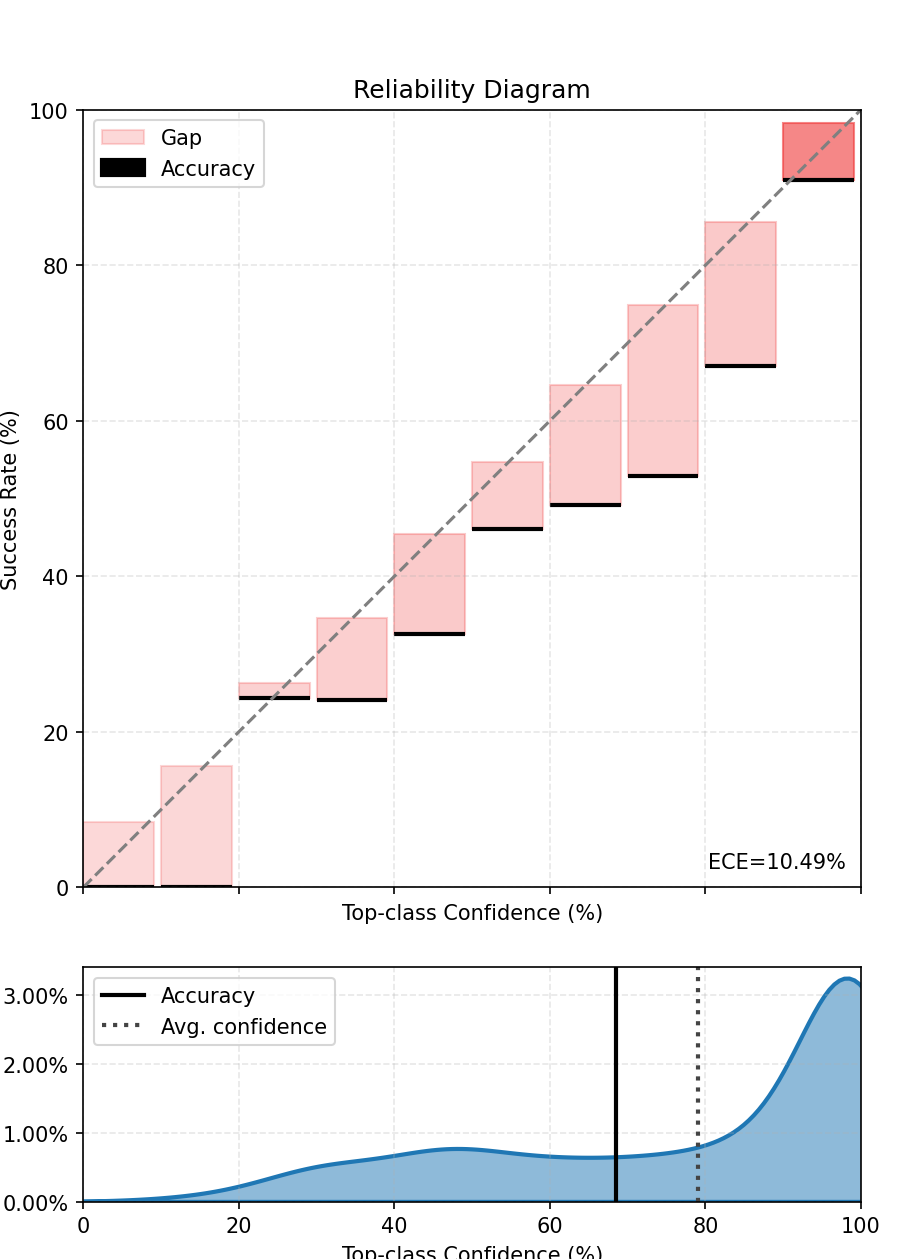
5. Fitting the Scaler to Improve the Calibration¶
The TemperatureScaler has one parameter that can be used to temper the softmax. We minimize the tempered cross-entropy on a calibration set that we define here as a subset of the test set and containing 1000 data. Look at the code run by TemperatureScaler fit method for more details.
# Fit the scaler on the calibration dataset
scaled_model = TemperatureScaler(model=model)
scaled_model.fit(dataloader=calibration_dataloader)
0%| | 0/32 [00:00<?, ?it/s]
6%|▋ | 2/32 [00:00<00:02, 13.71it/s]
12%|█▎ | 4/32 [00:00<00:02, 13.60it/s]
19%|█▉ | 6/32 [00:00<00:01, 13.58it/s]
25%|██▌ | 8/32 [00:00<00:01, 13.66it/s]
31%|███▏ | 10/32 [00:00<00:01, 13.66it/s]
38%|███▊ | 12/32 [00:00<00:01, 13.64it/s]
44%|████▍ | 14/32 [00:01<00:01, 13.61it/s]
50%|█████ | 16/32 [00:01<00:01, 13.59it/s]
56%|█████▋ | 18/32 [00:01<00:01, 13.62it/s]
62%|██████▎ | 20/32 [00:01<00:00, 13.65it/s]
69%|██████▉ | 22/32 [00:01<00:00, 13.65it/s]
75%|███████▌ | 24/32 [00:01<00:00, 13.64it/s]
81%|████████▏ | 26/32 [00:01<00:00, 13.68it/s]
88%|████████▊ | 28/32 [00:02<00:00, 13.73it/s]
94%|█████████▍| 30/32 [00:02<00:00, 13.71it/s]
100%|██████████| 32/32 [00:02<00:00, 13.96it/s]
6. Iterating Again to Compute the Improved ECE¶
We can directly use the scaler as a calibrated model.
Note that you will need to first reset the ECE metric to avoid mixing the scores of the previous and current iterations.
# Reset the ECE
ece.reset()
# Iterate on the test dataloader
for sample, target in test_dataloader:
logits = scaled_model(sample)
probs = logits.softmax(-1)
ece.update(probs, target)
print(f"ECE after scaling - {ece.compute():.3%}.")
ECE after scaling - 4.870%.
We finally compute and plot the scaled top-label calibration figure. We see that the model is now better calibrated.
fig, ax = ece.plot()
fig.show()
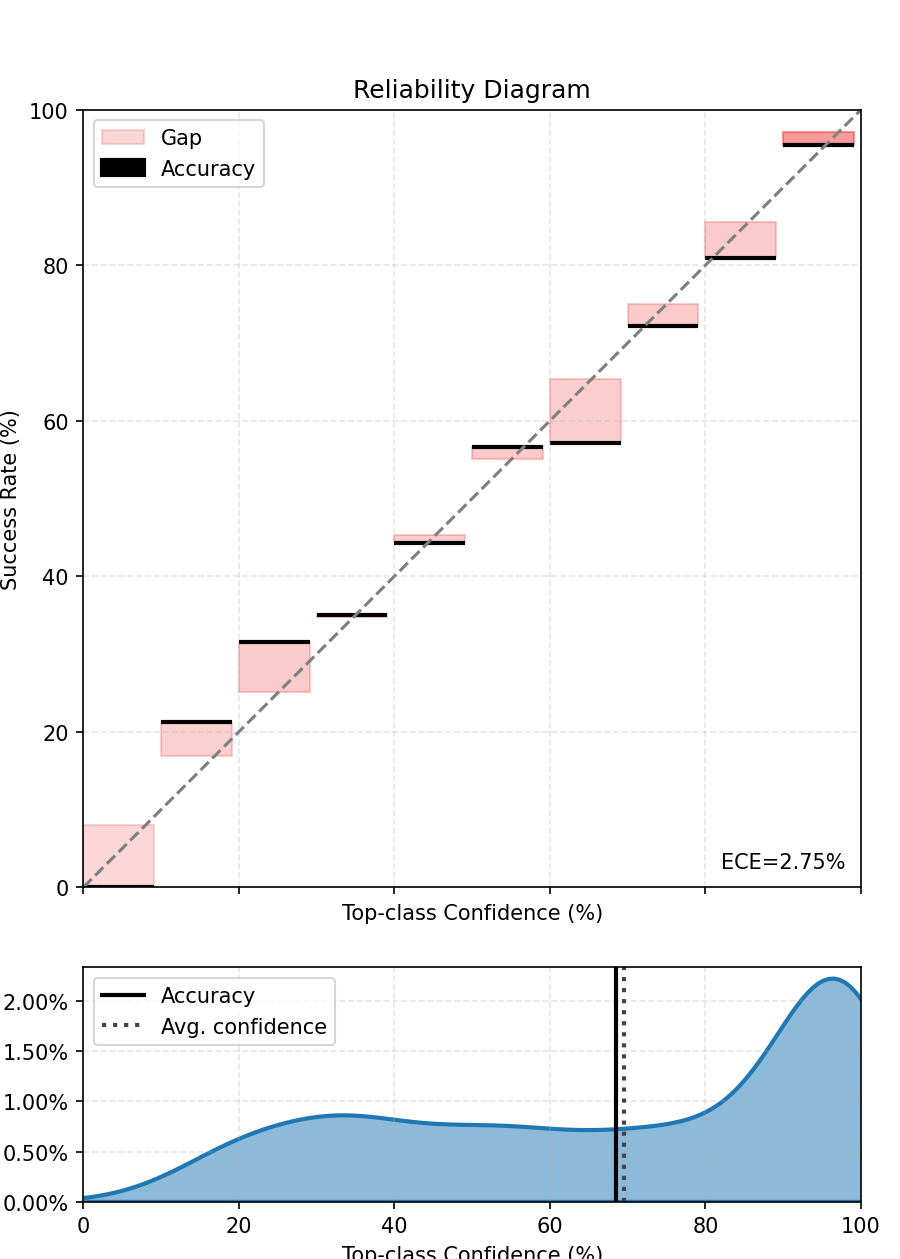
The top-label calibration should be improved.
Notes¶
Temperature scaling is very efficient when the calibration set is representative of the test set. In this case, we say that the calibration and test set are drawn from the same distribution. However, this may not hold true in real-world cases where dataset shift could happen.
References¶
Expected Calibration Error: Naeini, M. P., Cooper, G. F., & Hauskrecht, M. (2015). Obtaining Well Calibrated Probabilities Using Bayesian Binning. In AAAI 2015.
Temperature Scaling: Guo, C., Pleiss, G., Sun, Y., & Weinberger, K. Q. (2017). On calibration of modern neural networks. In ICML 2017.
Total running time of the script: (0 minutes 16.139 seconds)